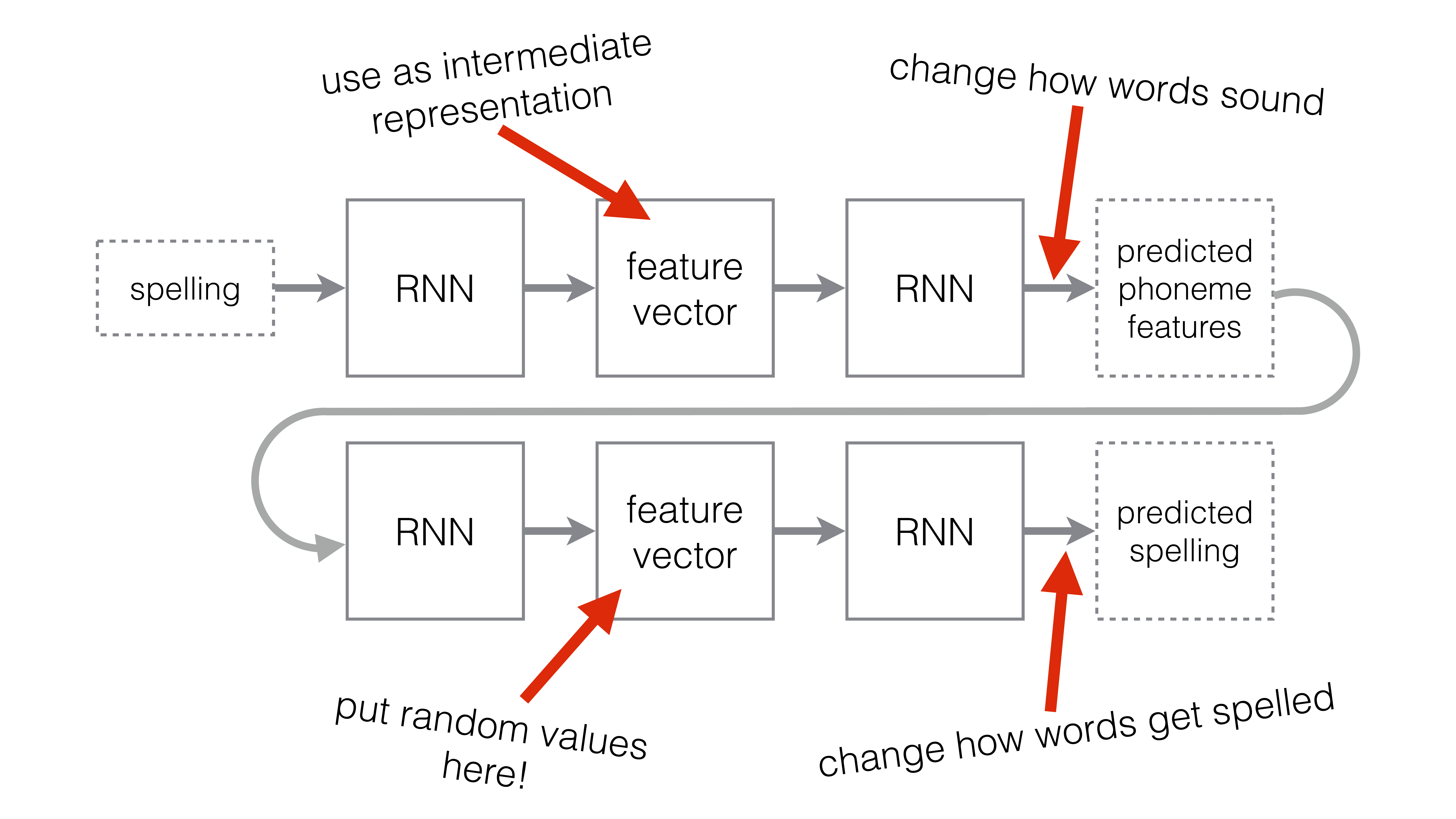
Allison's Bootleg Cart
2025
Allison's Bootleg Cart (ABC) is a flash cartridge for the Game Boy. You can copy Game Boy software from your computer to the cartridge, and then run that software on real hardware. The cartridge is based on Raspberry Pi's RP2040 chip, and makes extensive use of the PIO peripheral. My primary design goals were to use as little power as possible while also offering maximal compatibility and flexibility. I also wrote a lengthy article that contains pretty much everything I learned about Game Boy cartridges while undertaking this project. The cartridge design, firmware, and software are available under copyleft licenses.